How To Easily Scrape Web Content Using Python - No Tools Required
Are you a content manager or SEO expert (sorry, couldn’t resist lol) looking to extract web page copy for optimization campaigns or AI prompts? Frustrated by the struggle to get content via Screaming Frog or a lack of resources out there (like I was) on how to accomplish it easily? What about the litany of affiliate listicles of overly complicated freemium SaaS tools? (Spoiler, you don’t need them for this simple task!)
Well, if that’s you, you’re in the right place…
This beginner-friendly guide will teach you how to scrape web page content using Python, directly from your command prompt, without the need for a code editor. (Reach out to us today for a free SEO Consultation if you need more help with this guide!)
We'll cover everything from setting up Python on your computer to running a script that exports web page text, maintaining the order and structure as seen on the original page.
But first, let’s talk about what this script does…
What the Web Content Scrape Python Script Does
Before we jump into it, here’s a run down of what this script does and what it’s going to accomplish:
Reads URLs from a CSV File:
Imports URLs listed in a CSV file named
urls.csv.
Scrapes Web Pages:
Accesses each URL using the
requestslibrary.Fetches the HTML content of each web page.
Parses HTML Content:
Utilizes
BeautifulSoupfrombeautifulsoup4to parse the HTML content.Extracts specific elements (H1, H2, H3, H4, H5, H6, paragraphs, and hyperlinks) from the HTML.
Excludes Header and Footer:
Identifies and omits content in the
<header>and<footer>tags, as well as content in elements with class or IDheader/footer.
Formats and Saves Extracted Data:
Formats the text from each HTML element, annotating it with its tag name (e.g., "H1: Example Heading").
Includes hyperlinks in the text where they appear.
Saves the extracted and formatted content into individual text files, named after each URL.
Retries on Failure:
Implements a retry mechanism, attempting to scrape each URL up to 6 times in case of initial failures.
Generates a Status Report:
Creates a final CSV file named
final_url_status.csv.Lists each URL with its crawl status, indicating whether it was "Crawled Successfully" or "Failed to Crawl".
Error Handling and Troubleshooting:
Handles common errors like connection issues, missing files, and encoding problems.
Provides feedback in the command prompt for troubleshooting.
Potential Use Case Scenarios for SEOs and Content Managers
Competitor Content Analysis:
SEO professionals can use the script to scrape and analyze competitor websites.
Compare keyword strategies, heading structures, and content length.
Identify high-ranking content structures and topics in your industry.
Building AI-Driven Content Briefs:
Extract key elements from top-performing web pages to train AI models.
Use scraped data to create content briefs that align with proven successful formats.
Leverage AI tools to generate new content based on these data-driven briefs.
Backlink Opportunity Identification:
Scrape content to identify potential backlink opportunities.
Look for mentions of your brand or related topics without a link back to your site.
Reach out to these websites for backlinking, enhancing your SEO efforts.
Content Trend Analysis:
Scrape various blogs and news portals to identify trending topics.
Analyze frequently used keywords and subjects to guide your content creation strategy.
Stay ahead of the curve by producing content on emerging trends.
Monitoring Competitor Price Changes and Offers:
E-commerce SEO specialists can scrape competitor pricing and special offers.
Adjust your pricing strategies based on market trends.
Use this data to create competitive offers and discounts on your platform.
Integrating with Content Management Systems (CMS):
Automate the process of uploading scraped content to CMS like WordPress or Shopify.
Use scripts to format and prepare content for direct publishing or further editing.
Automated Content Archiving:
Use the script to create an archive of your own web content periodically.
Maintain a backup of web content for record-keeping or compliance purposes.
Training Data for Machine Learning Models in Content Generation:
Utilize scraped data as training material for machine learning models focused on content generation.
Create more accurate and industry-specific AI models for content creation.
Incorporating Content Web Scraping into Larger Workflows
For SEOs and content managers, web scraping can be an integral part of a larger workflow:
Initial Research: Start with scraping for competitive analysis, keyword identification, and understanding content structure trends.
Strategy Development: Use insights from scraped data to build robust content and SEO strategies.
Content Creation: Incorporate AI and machine learning tools to generate content briefs and drafts based on scraped data.
Publishing and Distribution: Seamlessly integrate scraped and AI-generated content into CMS for publishing.
Performance Monitoring: Continuously scrape competitor and industry data to monitor performance and adjust strategies accordingly.
Step 1: Setting Up Your Python Environment
Before we get started, you'll need to have Python installed on your computer. If you don't have Python installed yet, follow these steps:
Go to the official Python website.
Download the latest version of Python.
Open the downloaded file and follow the instructions to install Python.
After installing Python, we'll need to install a few Python libraries that we'll be using in this project: beautifulsoup . Here's how you can install this library:
Open Command Prompt (on Windows) or Terminal (on macOS or Linux).
Type the following commands and press Enter:
pip install requests beautifulsoup4
This command will install the necessary Python libraries using pip, which is a package manager for Python.
beautifulsoup4: Beautiful Soup is a Python library designed for quick turnaround projects like screen-scraping. Its primary purpose is to parse and navigate the HTML and XML structures of web pages. It provides Pythonic idioms for iterating, searching, and modifying the parse tree, making it easier to work with HTML or XML documents.
Step 2: Preparing Your List of URLs to be Crawled and Scraped
For this project, you'll need one Excel file saved in a “csv” format that will have the list of URLs that you want to scrape the content of. Check out the steps below:
Open Excel and paste your list of URLs into column A (The structure here is important!) There should only be one column here and it does not need a header (in fact, if it has anything other than urls in column A, it may mess up your script!)
Save the file as “urls.csv”. This should be done using the “CSV (command delimited) *.csv” option when saving the file. Note, the python script in this guide is not set up for use with .xlsx or other file types. The script will not work if it’s not a csv file.
Place that CSV file in the folder where you will eventually save the python script to. This will be the same folder (wherever that is, I usually place it on my desktop for ease of access) where you will eventually RUN the python script as well.
Here’s an example of where you might store that folder (which can be named what ever you want): “
C:\Users\YourUsername\Documents\PythonScripts\scraped-webcontent-project”

You’re all set here!
As a side note: I would test the script first using a handful of URLs before you go hard into the paint. The script has a 2 second delay between each URL in the list to account for error handeling and reattemps at crawling (eg. if the script hit a 429 error because of too many requests to the server), so keep that in mind
Step 3: Creating the Script.py File to Run via Command Prompt
For this project, you'll need one python script file saved in the “.py” format that will have the actual python script that you will be running via the command prompt terminal. Here’s how to prepare that file:
Open Notepad: Use Notepad or any text editor.
Create the Script: Copy and paste the script from below these steps directly into the blank Notepad. (See the full code below these steps)
Save the Script: Save as “scrape.py” in the same folder as urls.csv. (Choose All Files and append .py to save as “.py”).
import requests
from bs4 import BeautifulSoup
import csv
import os
import time
def sanitize_filename(url):
""" Sanitize the URL to be used as a filename """
return url.replace("http://", "").replace("https://", "").replace("/", "_").replace(":", "_")
def format_tag_with_links(tag):
""" Format tag text to include hyperlinks """
for a in tag.find_all('a', href=True):
link_text = a.text.strip()
if link_text:
a.replace_with(f"{link_text} (Link: {a['href']})")
return tag.get_text(strip=True)
def extract_and_save_content(url, output_folder):
try:
response = requests.get(url)
if response.status_code != 200:
return f"HTTP Error: {response.status_code}"
soup = BeautifulSoup(response.text, 'html.parser')
# Exclude header and footer
for header_footer in soup.find_all(['header', 'footer'], recursive=True):
header_footer.decompose()
for header_footer in soup.find_all(class_=['header', 'footer'], recursive=True):
header_footer.decompose()
for header_footer in soup.find_all(id=['header', 'footer'], recursive=True):
header_footer.decompose()
filename = f"{sanitize_filename(url)}.txt"
output_path = os.path.join(output_folder, filename)
with open(output_path, 'w', encoding='utf-8') as file:
for tag in soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'p']):
formatted_text = format_tag_with_links(tag)
if formatted_text:
file.write(f"{tag.name.upper()}: {formatted_text}\n\n")
if not os.path.getsize(output_path) > 0:
return "No relevant content extracted"
return True
except requests.RequestException as e:
return str(e)
def process_urls_from_csv(csv_file, output_folder, delay=2):
urls_to_process = {} # Dictionary to keep track of retries
url_status = {} # Dictionary to keep final status
with open(csv_file, newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
url = row[0].strip()
if url:
urls_to_process[url] = 6 # Initialize retry count for each URL
while urls_to_process:
for url, attempts in list(urls_to_process.items()):
status = extract_and_save_content(url, output_folder)
if status is True:
url_status[url] = "Crawled Successfully"
del urls_to_process[url]
else:
if attempts > 1:
urls_to_process[url] -= 1
else:
url_status[url] = "Failed to Crawl"
del urls_to_process[url]
time.sleep(delay)
# Write final URL status to a CSV file
with open(os.path.join(output_folder, "final_url_status.csv"), 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['URL', 'Status'])
for url, status in url_status.items():
writer.writerow([url, status])
print("URL processing status recorded in 'final_url_status.csv'.")
csv_file = 'urls.csv'
output_folder = 'extracted_contents'
os.makedirs(output_folder, exist_ok=True)
process_urls_from_csv(csv_file, output_folder)Step 4: Running the Python Script
Now that you have your Python script is ready (see, not so hard!), you can run it using command prompt on Windows to scrape your target list of URLs content.
Open Command Prompt on windows
You can do this by going to the Start button on your tool bar and searching for “cmd” or by searching for “command prompt”
Once command prompt is open, use a terminal command to navigate to the folder where you saved your Python scripts. You can do this by typing in “
cd“ followed by the folder path. (Make sure there is a space between “cd” and your folder path). Then hit “enter” and your command prompt should look something like what is pictured below. An exmample of the pathy you might use can also be seen directly below this step.
cd C:\Users\YourUsername\Documents\PythonScripts\KeywordCategorization\
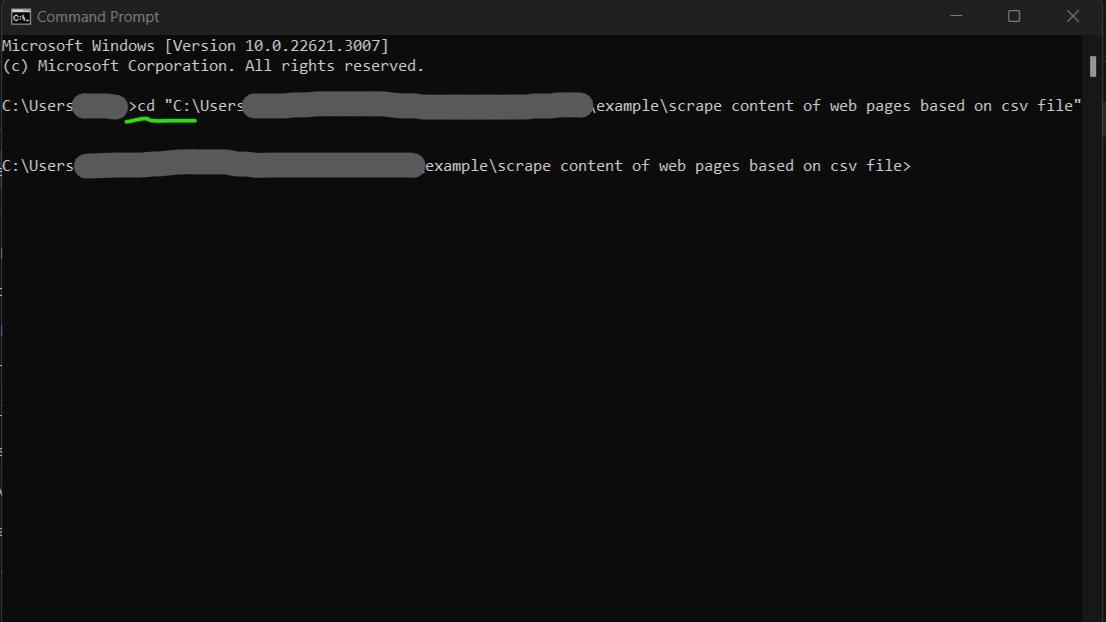
Side Note: You can also copy the path of the folder containing the script by right clicking and selecting “copy path”.
The Fun Part! Running the Script:
After navigating to the folder via the command prompt, type in “python scrape.py” and hit “enter”.
The script will automatically create a new folder WITHIN the folder that’s containing it named “extracted_contents” and if you open it, you will start to see it populated with your .txt files based on the list of URLs. (Cool right???)

How to Know When It’s Done:
You’ll know that the script is finished from two different things.
The command prompt terminal will “reset” and look like it’s back at the folder extension before your ran the script
There will be an excel .csv file that has the status of all of the URLs in it. This file will let you know if the script was successful for each URL. Usually it is, but sometimes you may see errors. Feel free to repeat the process, in a new folder, with the URLs you want to try again to get the scrape for.


Troubleshooting Common Errors
If you encounter any errors while running the Python script, here are a few common issues and how you can resolve them:
1. ModuleNotFoundError: If a module is not found, ensure required libraries are installed (pip install requests beautifulsoup4).
2. FileNotFoundError: Ensure urls.csv is in the same folder as your script.
3. Encoding Errors: Add encoding='utf-8' to file operations to handle character encoding issues.
4. requests.exceptions.ConnectionError: Check your internet connection and the URL's correctness.
5. Incomplete Data Scraped: The website's structure might differ from the script's assumptions. Adjust the script's parsing logic as needed.
6. HTTP Error 429: Too Many Requests: Implement delays between requests or scrape during off-peak hours.
7. Script Runs But No Output Files: Check the output folder's existence and the script's element identification logic.
Considerations When Using a Mac
Here's a bulletized list of considerations for Mac users who want to use this web scraping script:
Python Installation Check:
Verify if Python is pre-installed by typing
python --versionorpython3 --versionin the Terminal.If not installed, download Python from the official website.
Installing Libraries:
Use
pip3for installing libraries if Python 3 is not the default version:pip3 install requests beautifulsoup4.
Using Terminal:
Utilize the Terminal (found in Applications under Utilities) instead of the Command Prompt.
Navigating Directories in Terminal:
Use the
cdcommand with Unix-style paths, e.g.,cd /Users/YourName/Documents/MyScripts.
Running the Script:
Execute the script with
python3 scrape.pyin the Terminal, or justpythonif Python 3 is the default.
File Paths:
Ensure file paths in the script follow Unix-style formatting.
Permissions and Security Settings:
Adjust permissions or confirm security exceptions as needed for running scripts or installing libraries.
Text Editor for Editing Scripts:
Use built-in text editors like TextEdit, or download code-specific editors like Sublime Text or Visual Studio Code.
Handling Python Versions:
Be aware of which Python version (2.x or 3.x) is being used. Macs might come with Python 2 pre-installed.
Script Compatibility:
The script is generally cross-platform, but always test it first to ensure it works as expected on macOS.
In this guide, we've walked through how you can use Python to scrape only the most important content on web pages in bulk. Hope you find this helpful, happy content writing!
Feeling lost in all this technical SEO jargon and content marketing automation?
We can help. Reach out to us and we’ll help you stand out from the pack by optimizng your site and company’s SEO presence.